Cómo instalar Scrapy, una herramienta de rastreo web en Ubuntu
Scrapy es un software de código abierto que se utiliza para extraer datos de sitios web. Scrapy framework está desarrollado en Python y realiza el trabajo de rastreo de una manera rápida, simple y extensible. Hemos creado una máquina virtual (VM) en una caja virtual y Ubuntu 14.04 LTS está instalado en ella.
Instalar Scrapy
Scrapy depende de Python, bibliotecas de desarrollo y software pip. La última versión de Python está preinstalada en Ubuntu. Así que tenemos que instalar las bibliotecas de desarrollo pip y python antes de la instalación de Scrapy.
Pip es el reemplazo de easy_install para el indexador de paquetes de Python. Se utiliza para la instalación y gestión de paquetes de Python.
Para instalar el paquete pip, ejecute:
$ sudo apt-get install python-pip
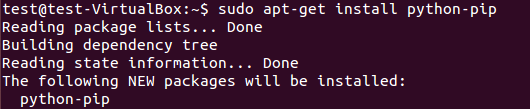
Tenemos que instalar las bibliotecas de desarrollo de Python usando el siguiente comando. Si este paquete no está instalado, la instalación de scrapy framework genera un error sobre el archivo de encabezado python.h.
$ sudo apt-get install python-dev

Scrapy framework se puede instalar desde el paquete deb o desde el código fuente. Sin embargo, hemos instalado el paquete deb usando pip (administrador de paquetes de Python).
$ sudo pip install scrapy
La instalación exitosa de Scrapy lleva algún tiempo.

Extracción de datos utilizando el marco Scrapy
(Tutorial básico)
Usaremos Scrapy para la extracción de los nombres de las tiendas (que proporcionan Tarjetas) del sitio web fatwallet.com. En primer lugar, creamos un nuevo proyecto scrapy «store_name» usando el siguiente comando.
$ sudo scrapy startproject store_name
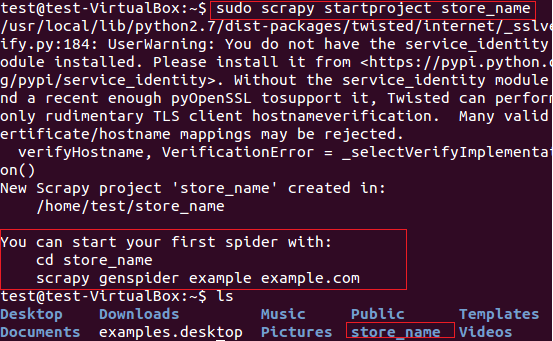
El comando anterior crea un directorio con el título «store_name» en la ruta actual. Este directorio principal del proyecto contiene archivos / carpetas que se muestran en la siguiente Figura 6.
$ sudo ls –lR store_name
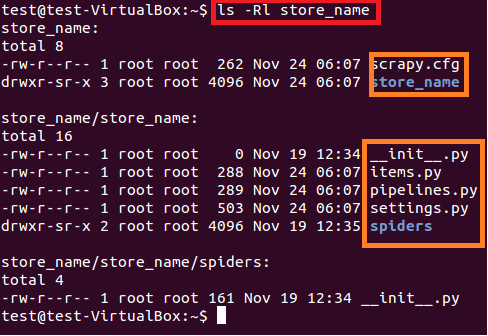
A continuación se ofrece una breve descripción de cada archivo / carpeta:
- scrapy.cfg es el archivo de configuración del proyecto
- store_name / es otro directorio dentro del directorio principal. Este directorio contiene el código Python del proyecto.
- store_name / items.py contiene aquellos elementos que serán extraídos por la araña.
- store_name / pipelines.py es el archivo de canalizaciones.
- La configuración del proyecto store_name está en el archivo store_name / settings.py.
- y el directorio store_name / spiders /, contiene spider para el rastreo
Como estamos interesados en extraer los nombres de las tiendas de las Tarjetas del sitio fatwallet.com, actualizamos el contenido del archivo como se muestra a continuación.
import scrapy class StoreNameItem(scrapy.Item): name = scrapy.Field() # extract the names of Cards store
Después de esto, tenemos que escribir new spider en el directorio store_name / spiders / del proyecto. Spider es una clase de Python que consta de los siguientes atributos obligatorios:
-
Nombre de la araña (nombre)
- URL de inicio de la araña para rastrear (start_urls)
-
Y el método de análisis que consiste en expresiones regulares para la extracción de elementos deseados de la respuesta de la página. El método de análisis es la parte importante de la araña.
Creamos la araña «store_name.py» en el directorio store_name / spiders / y agregamos el siguiente código de Python para la extracción del nombre de la tienda del sitio fatwallet.com. La salida de la araña se escribe en el archivo (StoreName.txt).
from scrapy.selector import Selector
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.http import FormRequest
import re
class StoreNameItem(BaseSpider):
name = "storename"
allowed_domains = ["fatwallet.com"]
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
def parse(self,response):
output = open('StoreName.txt','w')
resp = Selector(response)
tags = resp.xpath('//tr[@class="storeListRow"]|
//tr[@class="storeListRow even"]|
//tr[@class="storeListRow even last"]|
//tr[@class="storeListRow last"]').extract()
for i in tags:
i = i.encode('utf-8', 'ignore').strip()
store_name = ''
if re.search(r"class="storeListStoreName">.*?<",i,re.I|re.S):
store_name = re.search(r"class="storeListStoreName">.*?<",i,re.I|re.S).group()
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
#print store_name
output.write(store_name+""+"n")
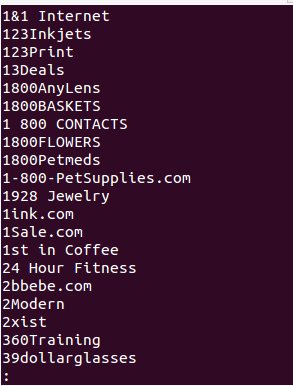
NOTA: El propósito de este tutorial es solo la comprensión de Scrapy Framework