Cómo configurar el clúster de varios nodos de Hadoop en Ubuntu
En este tutorial, aprenderemos cómo configurar un clúster hadoop de múltiples nodos en Ubuntu 16.04. Un clúster hadoop que tiene más de 1 nodo de datos es un clúster hadoop de múltiples nodos, por lo tanto, el objetivo de este tutorial es poner en funcionamiento 2 nodos de datos.
1) Requisitos previos
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
Para este tutorial, tengo dos ubuntu 16.04 sistemas, los llamo Maestro y esclavo sistema, un nodo de datos se ejecutará en cada sistema.
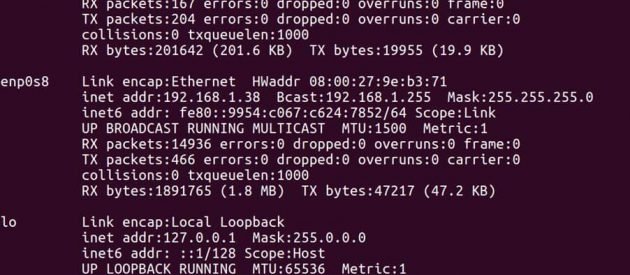
Dirección IP de Maestría -> 192.168.1.37
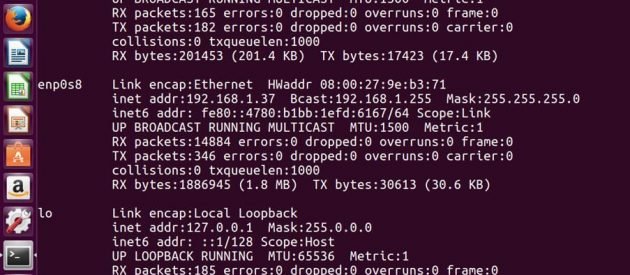
Dirección IP de Esclavo -> 192.168.1.38
En maestro
Edite el archivo de hosts con la dirección IP maestra y esclava.
sudo gedit /etc/hosts
Edite el archivo como se muestra a continuación, puede eliminar otras líneas en el archivo. Después de editar, guarde el archivo y ciérrelo.

En esclavo
Edite el archivo de hosts con la dirección IP maestra y esclava.
sudo gedit /etc/hosts
Edite el archivo como se muestra a continuación, puede eliminar otras líneas en el archivo. Después de editar, guarde el archivo y ciérrelo.

2) Instalación de Java
Antes de configurar hadoop, debe tener Java instalado en sus sistemas. Instale JDK 7 abierto en ambas máquinas ubuntu usando los siguientes comandos.
sudo add-apt-repository ppa:openjdk-r/ppa
sudo apt-get update
do apt-get install openjdk-7-jdk
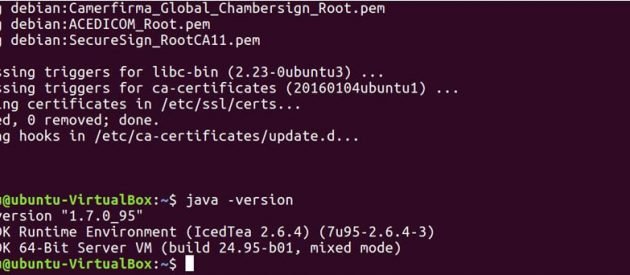
Ejecute el siguiente comando para ver si Java se instaló en su sistema.
java -version
Por defecto, java se almacena en / usr / lib / jvm / directorio.
ls /usr/lib/jvm

Establecer la ruta de Java en .bashrc expediente.
sudo gedit .bashrc
exportar JAVA_HOME = / usr / lib / jvm / java-7-openjdk-amd64
RUTA de exportación = $ RUTA: / usr / lib / jvm / java-7-openjdk-amd64 / bin
Ejecute el siguiente comando para actualizar los cambios realizados en el archivo .bashrc.
source .bashrc
3) SSH
Hadoop requiere acceso SSH para administrar sus nodos, por lo tanto, necesitamos instalar ssh en los sistemas maestro y esclavo.
sudo apt-get install openssh-server</preAhora, tenemos que generar una clave SSH en máquina maestra. Cuando le pida que ingrese un nombre de archivo para guardar la clave, no dé ningún nombre, simplemente presione enter.
ssh-keygen -t rsa -P ""

En segundo lugar, debe habilitar el acceso SSH a su máquina maestra con esta clave recién creada.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
![]()
![]()
Ahora pruebe la configuración de SSH conectándose a su máquina local.
ssh localhost
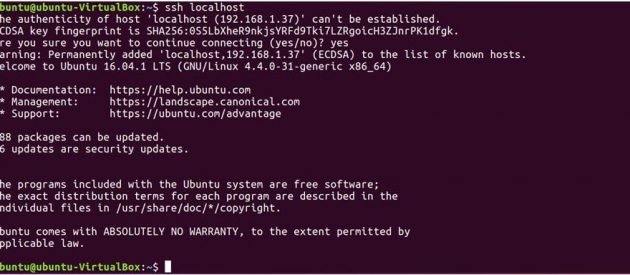
Ahora ejecute el siguiente comando para enviar la clave pública generada en el maestro al esclavo.
ssh-copy-id -i $HOME/.ssh/id_rsa.pub ubuntu@slave

Ahora que tanto el maestro como el esclavo tienen la clave pública, puede conectar maestro a maestro y maestro a esclavo también.
ssh master

ssh slave

En maestro
Edite el archivo maestro como se muestra a continuación.
sudo gedit hadoop-2.7.3/etc/hadoop/masters

Edite el archivo de esclavos como se muestra a continuación.
sudo gedit hadoop-2.7.3/etc/hadoop/slaves

En esclavo
Edite el archivo maestro como se muestra a continuación.
sudo gedit hadoop-2.7.3/etc/hadoop/masters
4) Instalación de Hadoop
Ahora que tenemos nuestra configuración de java y ssh lista. Estamos listos para instalar hadoop en ambos sistemas. Utilice el siguiente enlace para descargar el paquete hadoop. Estoy usando la última versión estable hadoop 2.7.3
http://hadoop.apache.org/releases.html

En maestro
El siguiente comando se descargará hadoop-2.7.3 tar archivo.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz
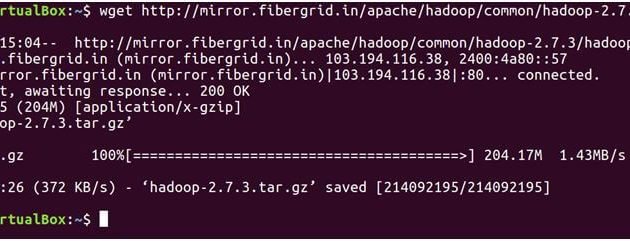
ls
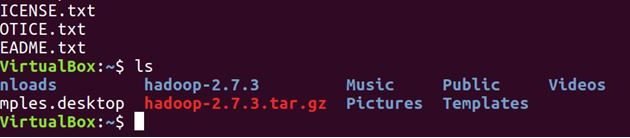
Desempaquetar el archivo
tar -xvf hadoop-2.7.3.tar.gz

ls
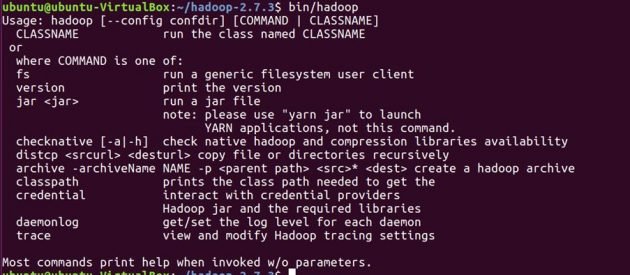
Confirme que hadoop se haya instalado en su sistema.
cd hadoop-2.7.3/ bin/hadoop-2.7.3/
Antes de establecer configuraciones para hadoop, estableceremos las siguientes variables de entorno en el archivo .bashrc.
cd sudo gedit .bashrc
Variables de entorno de Hadoop
# Set Hadoop-related environment variables export HADOOP_HOME=$HOME/hadoop-2.7.3 export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3 export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3 export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3 export YARN_HOME=$HOME/hadoop-2.7.3 # Add Hadoop bin/ directory to PATH export PATH=$PATH:$HOME/hadoop-2.7.3/bin

Ponga debajo de las líneas al final de su .bashrc archivo, guarde el archivo y ciérrelo.
source .bashrc
Configurar JAVA_HOME en ‘hadoop-env.sh’. Este archivo especifica las variables de entorno que afectan el JDK utilizado por los demonios de Apache Hadoop 2.7.3 iniciados por los scripts de inicio de Hadoop:
cd hadoop-2.7.3/etc/hadoop/
sudo gedit hadoop-env.sh

exportar JAVA_HOME = / usr / lib / jvm / java-7-openjdk-amd64

Establezca la ruta de Java como se muestra arriba, guarde el archivo y ciérrelo.
Ahora crearemos NameNode y DataNode directorios.
cd mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanode

Hadoop tiene muchos archivos de configuración, que deben configurarse según los requisitos de su infraestructura de Hadoop. Configuremos los archivos de configuración de hadoop uno por uno.
cd hadoop-2.7.3/etc/hadoop/ sudo gedit core-site.xml
Core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
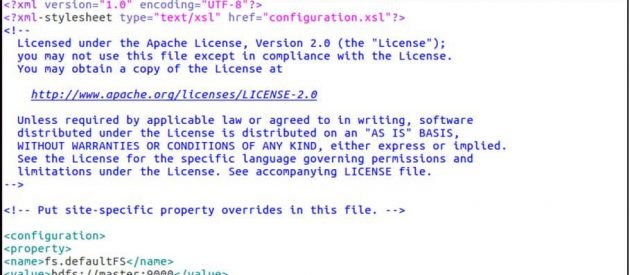
sudo gedit hdfs-site.xml
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value> </property> </configuration>
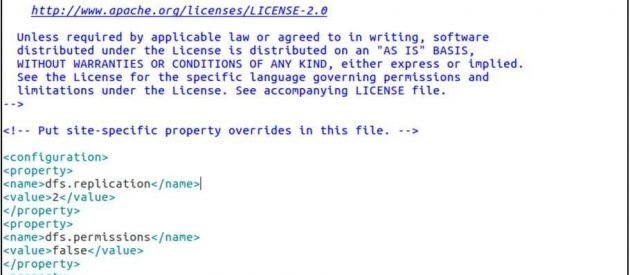
sudo gedit yarn-site.xml
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>

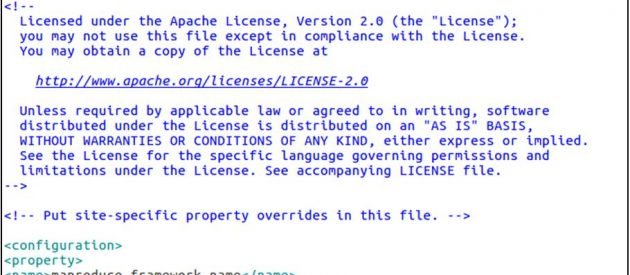
cp mapred-site.xml.template mapred-site.xml sudo gedit mapred-site.xml
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
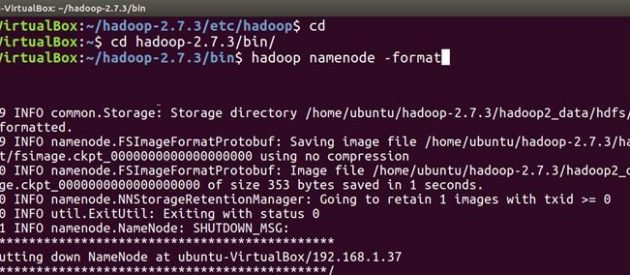
Ahora siga los mismos pasos de instalación y configuración de hadoop en la máquina esclava. Una vez que haya instalado y configurado hadoop en ambos sistemas, lo primero que debe hacer para iniciar su clúster de hadoop es formateo El hsistema de archivos adoop, que se implementa sobre los sistemas de archivos locales de su clúster. Esto es necesario la primera vez que se instala hadoop. No formatee un sistema de archivos hadoop en ejecución, esto borrará todos sus datos HDFS.
En maestro
cd cd hadoop-2.7.3/bin hadoop namenode -format
Ahora estamos listos para iniciar los demonios hadoop, es decir. NameNode, DataNode, ResourceManager y NodeManager en nuestro Apache Hadoop Cluster.
cd ..
Ahora ejecute el siguiente comando para iniciar NameNode en la máquina maestra y DataNodes en maestro y esclavo.
sbin/start-dfs.sh
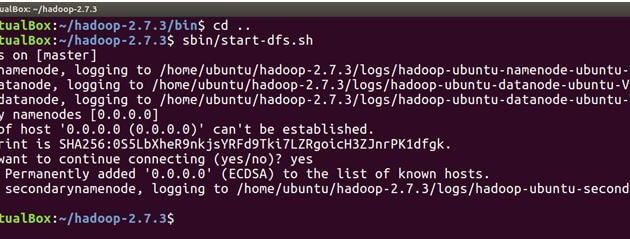
El siguiente comando iniciará los demonios YARN, ResourceManager se ejecutará en el maestro y NodeManagers se ejecutará en el maestro y el esclavo.
sbin/start-yarn.sh

Verifique que todos los servicios se hayan iniciado correctamente utilizando JPS (Java Process Monitoring Tool). tanto en la máquina maestra como en la esclava.
A continuación se muestran los demonios que se ejecutan en la máquina maestra.
jps
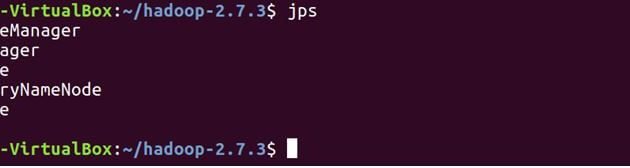
En esclavo
Verá que DataNode y NodeManager también se ejecutarán en la máquina esclava.
jps

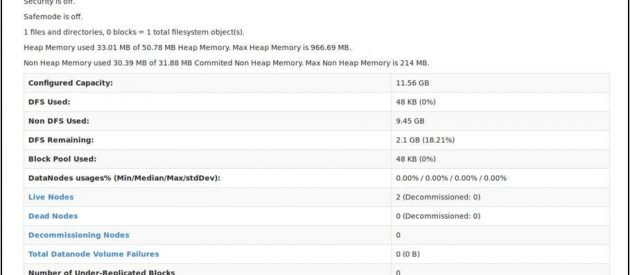
Ahora abra su navegador mozilla en la máquina maestra y vaya a la siguiente URL
Verifique el estado de NameNode: http: // master: 50070 / dfshealth.html

Si tú ves ‘2’ en nodos vivos, eso significa 2 DataNodes están en funcionamiento y ha configurado correctamente un hadoop culster de varios nodos.
Conclusión
Puede agregar más nodos a su clúster hadoop, todo lo que necesita hacer es agregar la nueva IP del nodo esclavo al archivo esclavo en el maestro, copiar la clave ssh al nuevo nodo esclavo, poner la IP maestra en el archivo maestro en el nuevo nodo esclavo y luego reiniciar el servicios de hadoop. ¡¡Felicidades!! Ha configurado correctamente un clúster de hadoop de varios nodos.