Cómo utilizar las herramientas de seguimiento del kernel de BCC para el análisis del rendimiento de Linux
Saludos, BCC ya está disponible para Ubuntu y en este artículo le mostraremos su uso extendido de la línea de comandos para rastrear sistemas Linux y monitorear el desempeño. BPF Compiler Collection (BCC) es un conjunto de herramientas para crear herramientas de rastreo del kernel que aprovechan la funcionalidad proporcionada por los filtros de paquetes Berkeley extendidos (BPF) de Linux. BPF garantiza que los programas cargados en el kernel no pueden fallar y no pueden ejecutarse para siempre, pero aún así BPF es lo suficientemente de propósito general para realizar muchos tipos arbitrarios de cálculo. BCC hace que los programas eBPF sean más fáciles de escribir, con instrumentación del kernel en C y un front-end en Python. Es adecuado para muchas tareas, incluido el análisis de rendimiento y el control del tráfico de la red. eBPF mejora el seguimiento de Linux, lo que permite que se ejecuten mini programas en eventos de seguimiento y le permite etiquetar eventos con marcas de tiempo personalizadas, almacenar histogramas, filtrar eventos y emitir información resumida a nivel de usuario. Estas capacidades brindan la información con el menor costo indirecto posible.
Requisitos previos:
Para instalar BCC, se requiere una versión del kernel de Linux 4.1 o más reciente. Si la versión de su kernel es diferente a la versión mencionada, entonces debería haber sido compilado con los siguientes indicadores establecidos en el ‘/boot/config-4.4.0-21-generic’ .
CONFIG_BPF=y CONFIG_BPF_SYSCALL=y # [optional, for tc filters] CONFIG_NET_CLS_BPF=m # [optional, for tc actions] CONFIG_NET_ACT_BPF=m CONFIG_BPF_JIT=y CONFIG_HAVE_BPF_JIT=y # [optional, for kprobes] CONFIG_BPF_EVENTS=y
Instalación de BCC (colección de compiladores BPF) en Ubuntu 16:
En Ubuntu 16.04 es necesario actualizar o cambiar los parámetros del kernel, simplemente ejecute los siguientes comandos para agregar su clave de origen en el repositorio y luego ejecute la actualización del sistema.
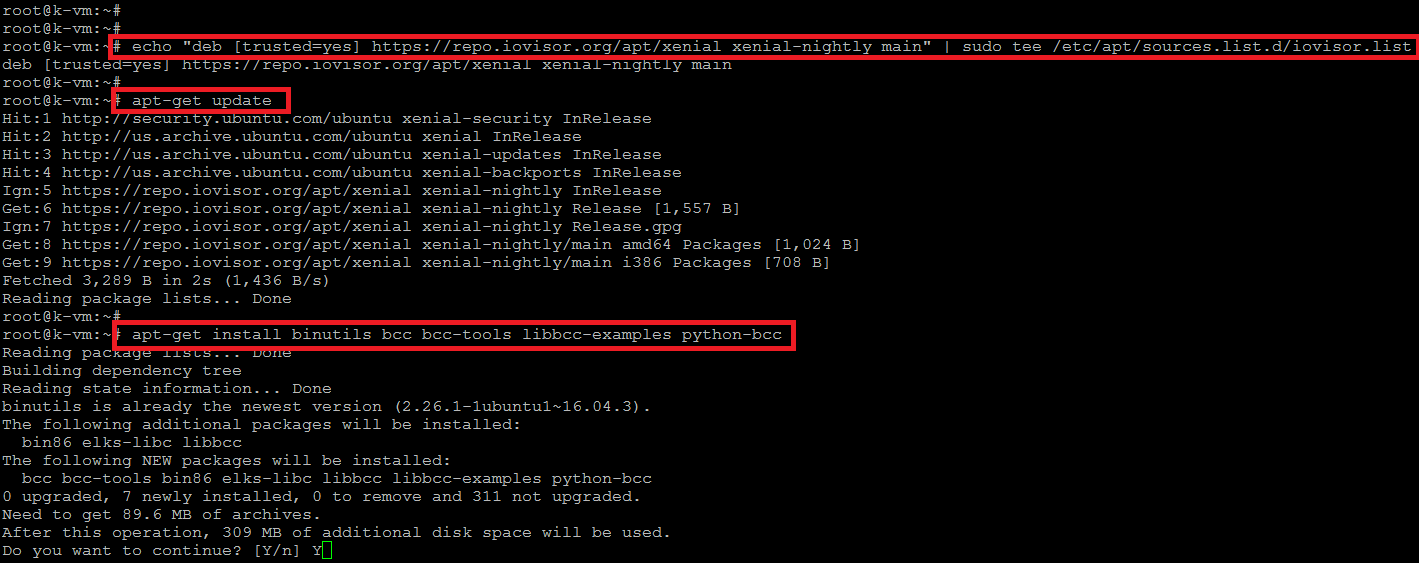
# echo "deb [trusted=yes] https://repo.iovisor.org/apt/xenial xenial-nightly main" | sudo tee /etc/apt/sources.list.d/iovisor.list
# apt-get update
Una vez que el sistema se haya actualizado, ejecute el siguiente comando para instalar bcc junto con algunas otras bibliotecas.
# apt-get install binutils bcc bcc-tools libbcc-examples python-bcc
Las herramientas BCC también están disponibles instantáneamente y se pueden instalar rápida y fácilmente con solo usar el siguiente comando en su terminal de línea de comandos.
# snap install --devmode bcc
Una vez completada la instalación, podemos probarla con los siguientes comandos de Python.
# python /usr/share/bcc/examples/hello_world.py
Obtendrá la imagen como se muestra a continuación.
-806 [001] d... 6685.522352: : Hello, World! -36641 [000] d... 6685.554148: : Hello, World! -36641 [000] d... 6695.999935: : Hello, World! -36644 [000] d... 6696.004081: : Hello, World! -36645 [000] d... 6696.007041: : Hello, World! -36646 [000] d... 6696.010295: : Hello, World! -36646 [000] d... 6696.011882: : Hello, World! -36646 [000] d... 6696.013417: : Hello, World! -36645 [000] d... 6696.014687: : Hello, World! -36650 [001] d... 6696.015892: : Hello, World! -36650 [001] d... 6696.016025: : Hello, World!
# python /usr/share/bcc/examples/tracing/task_switch.py
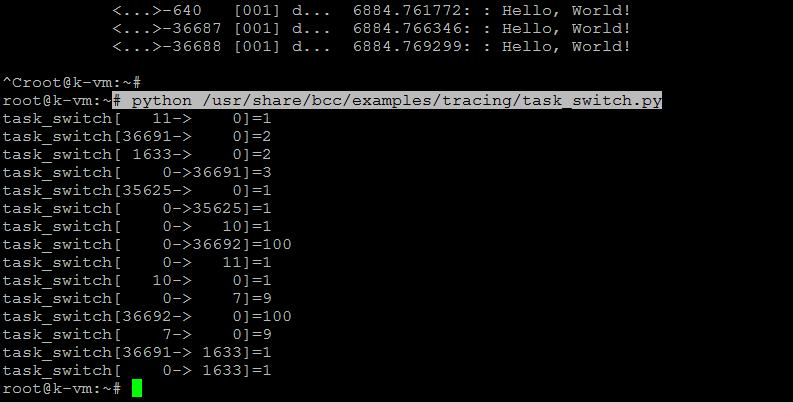
Usando BCC Tools en Ubuntu:
Actualmente hay alrededor de 70 herramientas BCC disponibles después de su instalación. A continuación, le mostraremos el uso de las herramientas más importantes y los trazados.
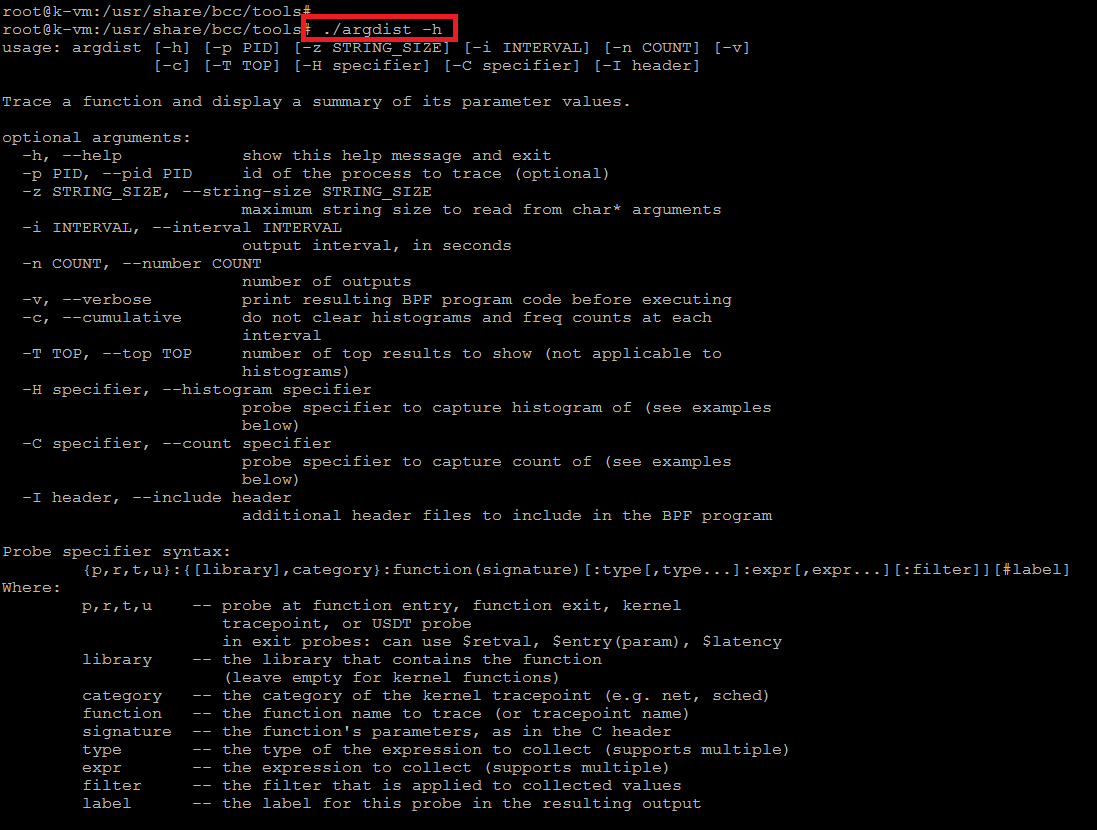
1) ardista
Muestra los valores de los parámetros de función como histograma o recuento de frecuencia. Para obtener ayuda detallada sobre el uso de esta herramienta, utilice el siguiente comando.
# argdist -h
Por ejemplo, deseaba pasar un histograma de tamaños de búfer a write ()
función en todo el sistema, ejecute el siguiente comando junto con los parámetros dados.
# ./argdist -c -H 'p:c:write(int fd, void *buf, size_t len):size_t:len'
[17:14:42] len : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 1 |****************************************| 16 -> 31 : 0 | | 32 -> 63 : 0 | | 64 -> 127 : 1 |****************************************| [17:14:43] len : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 2 |******** | 16 -> 31 : 0 | | 32 -> 63 : 1 |**** | 64 -> 127 : 10 |****************************************| 128 -> 255 : 3 |************ | 256 -> 511 : 1 |**** | [17:14:44]
Muestra que la mayoría de las escrituras se dividen en tres grupos: escrituras muy pequeñas de 2-3 bytes, escrituras medianas de 32-63 bytes y escrituras más grandes de 64-127 bytes.
2) línea de hilo
La herramienta bashreadline imprime comandos bash de todos los shells bash en ejecución en el sistema. Para usar esta herramienta, simplemente ejecute el comando como se muestra a continuación y obtendrá una lista de todos los comandos bash en ejecución.
# ./bashreadline
TIME PID COMMAND 11:28:35 21176 echo hello world 11:28:43 21176 foo this command failed 11:28:45 21176 df -h 11:29:04 3059 echo another shell 11:29:13 21176 echo first shell again
3) biolatencia
La biolatencia rastrea la E / S del dispositivo de bloque (E / S de disco) y registra la distribución de la latencia de E / S (tiempo), imprimiendo esto como un histograma cuando se presiona Ctrl-C.
# ./biolatency
Tracing block device I/O... Hit Ctrl-C to end. ^C usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 0 | | 16 -> 31 : 0 | | 32 -> 63 : 0 | | 64 -> 127 : 0 | | 128 -> 255 : 0 | | 256 -> 511 : 2 |****************************************|
Para mayor eficiencia, biolatency usa un mapa eBPF en el kernel para almacenar marcas de tiempo con solicitudes y otro mapa en el kernel para almacenar la columna de histograma (el «recuento»), que se copia en el espacio de usuario solo cuando se imprime la salida. Estos métodos reducen la sobrecarga de rendimiento cuando se realiza el seguimiento.
4) biotop
Biotop, abreviatura de block device I / O top, resume qué procesos están realizando E / S de disco. Es superior para discos y mostrará los resultados en el siguiente formato.
# ./biotop
Tracing... Output every 1 secs. Hit Ctrl-C to end 18:33:46 loadavg: 0.00 0.03 0.05 1/303 38817 PID COMM D MAJ MIN DISK I/O Kbytes AVGms 24301 cksum R 202 1 sda 361 28832 3.39 7961 dd R 202 1 sda 1628 13024 0.59
5) biosnop
El biosnoop rastrea la E / S del dispositivo de bloque (E / S de disco) e imprime una línea de salida por E / S. Esto incluye el PID y el comm (nombre del proceso) que estaban en la CPU en el momento de la emisión (que generalmente significa el proceso responsable). La latencia de la E / S del disco, medida desde el problema hasta el dispositivo hasta su finalización, se incluye como la última columna como se muestra a continuación.
# ./biosnoop
TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms) 0.000000000 ? 0 R -1 8 0.26 1.771303000 jbd2/sda1-8 192 sda W 17273608 8192 27.53 1.772083000 jbd2/sda1-8 192 sda W 17273624 4096 0.67 2.047987000 ? 0 R -1 8 0.26 4.095943000 ? 0 R -1 8 0.24 6.144020000 ? 0 R -1 8 0.26 8.191950000 ? 0 R -1 8 0.25 10.239991000 ? 0 R -1 8 0.27 12.288032000 ? 0 R -1 8 0.27 14.336013000 ? 0 R -1 8 0.25 16.384132000 ? 0 R -1 8 0.40 18.431956000 ? 0 R -1 8 0.24 20.479998000 ? 0 R -1 8 0.26 22.527986000 ? 0 R -1 8 0.28 24.576031000 ? 0 R -1 8 0.29 26.623940000 ? 0 R -1 8 0.24 28.671949000 ? 0 R -1 8 0.24 30.719936000 ? 0 R -1 8 0.25 32.767940000 ? 0 R -1 8 0.25
Esta salida de ejemplo es de lo que debería ser un sistema inactivo, sin embargo, lo siguiente es visible en la salida de iostat.
# iostat -x 1
Linux 4.4.0-21-generic (k-vm) 02/01/2017 _x86_64_ (2 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.82 1.20 0.37 0.52 0.00 97.10 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util loop0 0.00 0.00 0.01 0.00 0.10 0.00 31.32 0.00 0.14 0.14 0.00 0.06 0.00 loop1 0.00 0.00 0.01 0.00 0.03 0.00 11.23 0.00 0.03 0.03 0.00 0.03 0.00 sda 0.02 6.54 1.74 4.65 45.87 214.31 81.50 0.19 30.48 9.25 38.42 2.70 1.72 avg-cpu: %user %nice %system %iowait %steal %idle 0.00 0.00 0.00 0.00 0.00 100.00 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
6) tamaño de un bocado
El objetivo de esta herramienta es mostrar la distribución de E / S para los tamaños de bloque solicitados, por nombre de proceso.
# ./bitesize
Tracing... Hit Ctrl-C to end. ^C Process Name="jbd2/sda1-8" Kbytes : count distribution 0 -> 1 : 1 |****************************************| 2 -> 3 : 0 | | 4 -> 7 : 1 |****************************************| 8 -> 15 : 1 |****************************************|
7) capaz
Capable rastrea las llamadas a la función cap_capable () del kernel, que realiza verificaciones de capacidad de seguridad e imprime los detalles de cada llamada.
# ./capable
TIME UID PID COMM CAP NAME AUDIT 19:20:34 0 39820 capable 21 CAP_SYS_ADMIN 1 19:20:34 0 39820 capable 21 CAP_SYS_ADMIN 1 19:21:09 100 6022 systemd-timesyn 12 CAP_NET_ADMIN 1 19:22:09 0 647 systemd-logind 12 CAP_NET_ADMIN 1 19:22:09 0 17302 systemd-udevd 12 CAP_NET_ADMIN 1
El resultado anterior incluye varias comprobaciones de capacidad: snmpd comprobando CAP_NET_ADMIN, ejecute comprobando CAP_SYS_RESOURCES, luego algunos procesos de corta duración
comprobar CAP_FOWNER, CAP_FSETID, etc. Esto puede ser útil para la depuración general y también para la aplicación de seguridad, como determinar una lista blanca de capacidades que necesita una aplicación.
8) cachestat
cachestat se puede utilizar para mostrar una línea de estadísticas resumidas del caché del sistema cada segundo. Esto permite las operaciones de ajuste del sistema al señalar una baja tasa de aciertos de caché y una alta tasa de errores.
# ./cachestat
HITS MISSES DIRTIES READ_HIT% WRITE_HIT% BUFFERS_MB CACHED_MB 0 0 0 0.0% 0.0% 170 2156 3 3 1 33.3% 33.3% 170 2156 0 0 0 0.0% 0.0% 170 2156 0 0 0 0.0% 0.0% 170 2156 0 0 0 0.0% 0.0% 170 2156 0 0 0 0.0% 0.0% 170 2156 0 0 0 0.0% 0.0% 170 2156 ^C 0 0 0 0.0% 0.0% 170 2156
9) tapa de caché
cachetop muestra estadísticas de aciertos / errores de caché de páginas de Linux, incluido el porcentaje de aciertos de lectura y escritura por procesos en una interfaz de usuario como top.
# ./cachetop
20:07:24 Buffers MB: 171 / Cached MB: 2156 / Sort: HITS / Order: ascending PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT% 39844 root python 1 0 0 100.0% 0.0%
10) cpudista
Este programa resume el tiempo de la tarea en la CPU como un histograma, que muestra cuánto tiempo pasaron las tareas en la CPU antes de ser desprogramadas. Esto proporciona información valiosa que puede indicar exceso de suscripción (demasiadas tareas para muy pocos procesadores), sobrecarga debido a un cambio de contexto excesivo (por ejemplo, un bloqueo compartido común para varios subprocesos), distribución desigual de la carga de trabajo, tareas demasiado granulares y más.
# ./cpudist
Tracing on-CPU time... Hit Ctrl-C to end. ^C usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 1 | | 4 -> 7 : 3 | | 8 -> 15 : 1 | | 16 -> 31 : 4 | | 32 -> 63 : 2 | | 64 -> 127 : 4 | | 128 -> 255 : 5 | | 256 -> 511 : 9 | | 512 -> 1023 : 24 | | 1024 -> 2047 : 40 | | 2048 -> 4095 : 1615 |****************************************| 4096 -> 8191 : 9
A continuación se muestran algunos otros comandos que puede usar para monitorear la CPU de su sistema.
Para resumir el tiempo fuera de la CPU como un histograma
# ./cpudist -O
Para imprimir resúmenes de 1 segundo, 10 veces
# ./cpudist 1 10
Resúmenes de 1 s, milisegundos y marcas de tiempo
# ./cpudist -mT 1
Para mostrar cada PID por separado.
# ./cpudist -P
Para rastrear solo PID 185
# ./cpudist -p 185
11) dcsnoop
dcsnoop rastrea las búsquedas de la caché de entrada de directorio (dcache) y se puede usar para una investigación adicional más allá de dcstat (8). Es probable que el resultado sea detallado, ya que es probable que las búsquedas de dcache sean frecuentes. De forma predeterminada, solo se muestran las búsquedas fallidas.
# ./dcsnoop
TIME(s) PID COMM T FILE 1.777623 39844 python M meminfo 6.787286 39844 python M meminfo 8.912472 812 irqbalance M interrupts 8.912550 812 irqbalance M stat 11.795628 39844 python M meminfo 16.803827 39844 python M meminfo 18.912481 812 irqbalance M interrupts 18.912570 812 irqbalance M stat 21.812077 39844 python M meminfo 26.820298 39844 python M meminfo 28.912554 812 irqbalance M interrupts 28.912629 812 irqbalance M stat 31.828839 39844 python M meminfo
La salida muestra los procesos, el tipo de evento (columna «T»: M == falta, R == referencia) y el nombre de archivo para la búsqueda de dcache.
12) execsnoop
El execsnoop rastrea nuevos procesos. Por ejemplo, rastrear los comandos invocados al ejecutar «man rm».
# ./execsnoop
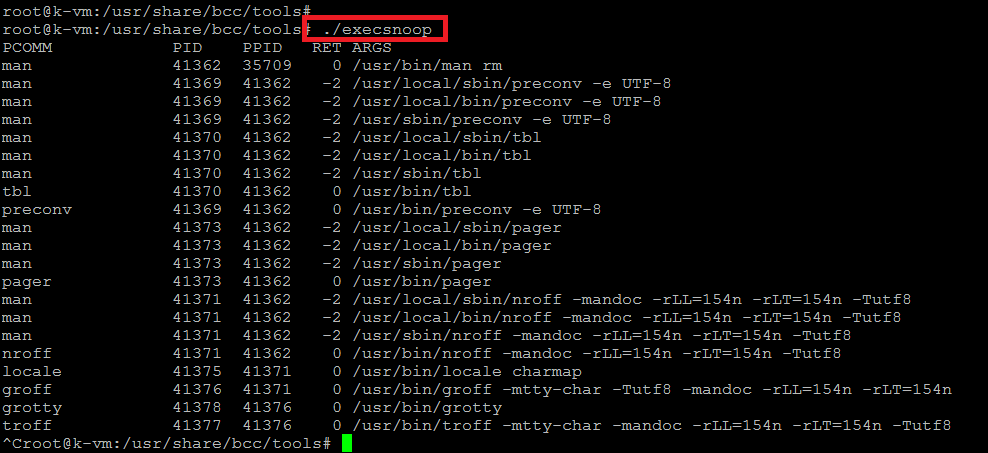
La salida muestra el nombre del proceso / comando principal (PCOMM), el PID, el valor de retorno de exec () (RET) y el nombre de archivo con argumentos (ARGS).
13) ext4dist
ext4dist rastrea las lecturas, escrituras, aperturas y fsyncs de ext4, y resume su latencia como un histograma de potencia de 2.
# ./ext4dist
Tracing ext4 operation latency... Hit Ctrl-C to end. ^C operation = 'read' usecs : count distribution 0 -> 1 : 44 |****************************************| 2 -> 3 : 20 |****************** | 4 -> 7 : 1 | | operation = 'write' usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 2 |****************************************| 16 -> 31 : 1 |******************** | operation = 'open' usecs : count distribution 0 -> 1 : 46 |****************************************| 2 -> 3 : 0 | | 4 -> 7 : 2 |* |
La salida muestra una distribución bimodal para la latencia de lectura, con un modo más rápido de menos de 7 microsegundos. La columna de recuento muestra cuántos eventos cayeron en ese rango de latencia. Es probable que el modo más rápido haya sido un éxito de la caché del sistema de archivos en la memoria, y el modo más lento sea una lectura de un dispositivo de almacenamiento (disco). Esta «latencia» se mide desde que se emitió la operación desde la interfaz VFS al sistema de archivos hasta que se completó.
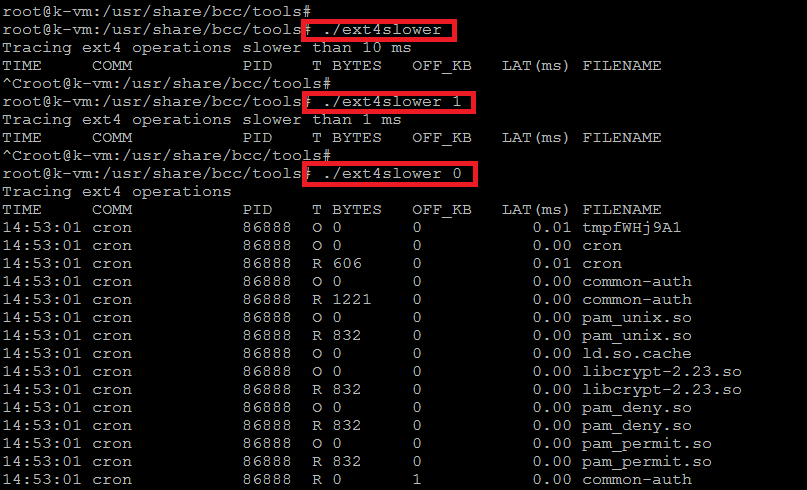
14) ext4slower
La herramienta Ext4slower rastrea operaciones comunes de archivos ext4 como lecturas, escrituras, aperturas y sincronizaciones. Mide el tiempo invertido en estas operaciones e imprime los detalles de cada uno que excedió un umbral.
De forma predeterminada, se utiliza un umbral mínimo de milisegundos de 10. Si se usa un umbral de 0, se imprimen todos los eventos. El archivo síncrono de seguimiento lee y escribe más lento que 10 ms.
#./ext4slower
Para rastrear más lento de 1 ms:
# ./ext4slower 1
Rastree más lento que 1 ms y genere solo los campos en formato analizable (csv), use el siguiente comando.
# ./ext4slower -j 1
Para rastrear todas las lecturas y escrituras de archivos, ejecute a continuación.
# ./ext4slower 0
Rastreo más lento que 1 ms, solo para PID 1182:
# ext4slower -p 1182 1
15) vida de archivo
filelife rastrea archivos de corta duración, aquellos que se han creado y luego eliminado durante el rastreo.
# ./filelife
TIME PID COMM AGE(s) FILE 14:35:01 41399 cron 0.00 tmpfnq6U0D 14:45:01 41403 cron 0.00 tmpf4FoYPW
Esto ha detectado archivos de corta duración que se crearon durante la compilación del kernel de Linux. El PID muestra el ID del proceso que finalmente eliminó el archivo, y COMM
es su nombre de proceso. La columna EDAD (s) muestra la antigüedad del archivo, en segundos, cuando se eliminó. Todos estos son de corta duración y existieron por menos de
una décima de segundo.
16) tapa de archivo
filetop muestra lecturas y escrituras por archivo, con detalles del proceso.
# ./filetop
14:47:25 loadavg: 0.00 0.01 0.05 1/302 41425 TID COMM READS WRITES R_Kb W_Kb T FILE 41425 clear 2 0 8 0 R xterm 812 irqbalance 4 0 4 0 R interrupts 812 irqbalance 4 0 4 0 R stat 41409 filetop 2 0 2 0 R loadavg 41425 clear 1 0 0 0 R libc-2.23.so 41425 clear 1 0 0 0 R libtinfo.so.5.9 41425 filetop 3 0 0 0 R clear 41425 filetop 2 0 0 0 R ld-2.23.so
Esto muestra varios archivos leídos y escritos durante la compilación del kernel de Linux. La salida se ordena por el tamaño total de lectura en Kbytes (R_Kb). Esto se instrumenta en la interfaz VFS, por lo que se trata de lecturas y escrituras que pueden regresar por completo desde la caché del sistema de archivos (caché de página).
17) cuenta funcional
Este programa rastrea funciones, puntos de rastreo o sondas USDT que coinciden con un patrón específico, y cuando se presiona Ctrl-C, imprime un resumen de su recuento.
mientras rastrea. Por ejemplo, rastrear todas las funciones del kernel que comienzan con «vfs_».
# ./funccount 'vfs_*'
Tracing 46 functions for "vfs_*"... Hit Ctrl-C to end. ^C FUNC COUNT vfs_statfs 2 vfs_unlink 2 vfs_create 2 vfs_lock_file 4 vfs_writev 90 vfs_fstatat 156 vfs_write 396 vfs_fstat 409 vfs_open 456 vfs_getattr 565 vfs_getattr_nosec 565 vfs_read 1600
Esto es útil para explorar el código del kernel, para averiguar qué funciones están en uso y cuáles no. Esto puede reducir una investigación a unas pocas funciones, cuyos recuentos son similares a la carga de trabajo investigada.
# ./funccount 'tcp_*'
Tracing 276 functions for "tcp_*"... Hit Ctrl-C to end. ^C FUNC COUNT tcp_delack_timer_handler 1 tcp_update_pacing_rate 1 tcp_send_delayed_ack 1 tcp_delack_timer 1 tcp_rack_advance 1 tcp_cwnd_restart 2 tcp_queue_rcv 2 tcp_check_space 2 tcp_event_data_recv 2 tcp_push 3 tcp_sendmsg 3 tcp_init_tso_segs 3 tcp_rearm_rto.part.56 4 tcp_release_cb 5 tcp_options_write 5 tcp_v4_md5_lookup 8 tcp_established_options 8 tcp_md5_do_lookup 11 tcp_poll 14
18) no se abre
opensnoop rastrea la llamada al sistema open () en todo el sistema e imprime varios detalles.
# ./opensnoop
PID COMM FD ERR PATH 812 irqbalance 3 0 /proc/interrupts 812 irqbalance 3 0 /proc/stat 812 irqbalance 3 0 /proc/interrupts 812 irqbalance 3 0 /proc/stat 812 irqbalance 3 0 /proc/interrupts 812 irqbalance 3 0 /proc/stat 1 systemd 21 0 /proc/6022/cgroup 1 systemd 21 0 /proc/647/cgroup 1 systemd 21 0 /proc/17302/cgroup 1 systemd 21 0 /proc/225/cgroup 812 irqbalance 3 0 /proc/interrupts 812 irqbalance 3 0 /proc/stat 812 irqbalance 3 0 /proc/interrupts 812 irqbalance 3 0 /proc/stat
Durante el seguimiento, el proceso systemd abrió varios archivos / proc (lectura de métricas) y un proceso de «ejecución» leyó varias bibliotecas y archivos de configuración. opensnoop puede ser útil para descubrir archivos de configuración y de registro, si se usa durante el inicio de la aplicación.
19) pidpersec
Esto muestra el número de nuevos procesos creados por segundo, medidos mediante el seguimiento de la rutina kernel fork ().
# ./pidpersec
Tracing... Ctrl-C to end. 16:27:27: PIDs/sec: 0 16:27:28: PIDs/sec: 0 16:27:29: PIDs/sec: 0 16:27:30: PIDs/sec: 0 16:27:31: PIDs/sec: 0 16:27:32: PIDs/sec: 0 16:27:33: PIDs/sec: 0 16:27:34: PIDs/sec: 0 16:27:35: PIDs/sec: 0 16:27:36: PIDs/sec: 0 16:27:37: PIDs/sec: 0
Cada segundo no hay nuevos procesos (esto pasa a ser causado por un script de inicio que se está reintentando en un bucle y encuentra errores). Cuando ejecute cualquier comando en la otra sesión, verá un aumento en su número de proceso.
20) statsnoop
statsnoop rastrea las diferentes llamadas al sistema stat () en todo el sistema e imprime varios detalles.
# ./statsnoop
PID COMM FD ERR PATH 640 cron 0 0 /etc/localtime 640 cron 0 0 crontabs 640 cron 0 0 /etc/crontab 640 cron 0 0 /etc/cron.d 640 cron 0 0 /etc/cron.d/anacron 640 cron 0 0 /etc/cron.d/popularity-contest 640 cron 0 0 /etc/cron.d/sysstat 640 cron 0 0 /etc/localtime 640 cron 0 0 crontabs 640 cron 0 0 /etc/crontab 640 cron 0 0 /etc/cron.d 640 cron 0 0 /etc/cron.d/anacron 640 cron 0 0 /etc/cron.d/popularity-contest 640 cron 0 0 /etc/cron.d/sysstat
statsnoop se puede utilizar para la depuración general, para ver qué información de archivo se ha solicitado y si esos archivos existen. Se puede utilizar como complemento de opensnoop, que muestra qué archivos se abrieron realmente.
21) syncsnoop
Este programa rastrea las llamadas a la rutina sync () del kernel, con marcas de tiempo básicas.
# ./syncsnoop
TIME(s) CALL 134548.6152 sync() 134151.5339 sync() ^C
Durante el seguimiento, el comando «sync» se ejecutó en otra sesión del servidor. Esto puede ser útil para identificar que se está llamando a sync () y su frecuencia.
22) tcptop
tcptop resume el rendimiento por host y puerto.
# ./tcptop
16:53:21 loadavg: 0.00 0.01 0.05 1/301 41994 PID COMM LADDR RADDR RX_KB TX_KB 36670 sshd 192.168.10.14:22 192.168.9.7:62379 0 0
Este resultado de ejemplo muestra dos listas de conexiones TCP, para IPv4 e IPv6. Si solo hay tráfico para uno de estos, solo se muestra un grupo.
23) rastro
Rastrear funciones arbitrarias, con filtros. rastrea las funciones que usted especifica y muestra mensajes de rastreo si un
se cumple la condición. Puede controlar el formato del mensaje para mostrar argumentos de función y valores de retorno.
Por ejemplo, suponga que desea rastrear todos los comandos que se ejecutan en el sistema.
# ./trace 'sys_execve "%s", arg1'
PID TID COMM FUNC - 42200 42200 bash sys_execve /bin/ls 42201 42201 bash sys_execve /usr/bin/man 42208 42208 man sys_execve /usr/local/sbin/preconv 42208 42208 man sys_execve /usr/local/bin/preconv 42208 42208 man sys_execve /usr/sbin/preconv 42208 42208 man sys_execve /usr/bin/preconv 42212 42212 man sys_execve /usr/local/sbin/pager 42212 42212 man sys_execve /usr/local/bin/pager 42212 42212 man sys_execve /usr/sbin/pager 42212 42212 man sys_execve /usr/bin/pager 42210 42210 man sys_execve /usr/local/sbin/nroff 42210 42210 man sys_execve /usr/local/bin/nroff
La sintaxis :: sys_execve especifica que desea una sonda de entrada (que es la predeterminada), en una función del kernel (que es la predeterminada) llamada sys_execve. A continuación, la cadena de formato para imprimir es simplemente «% s», que imprime una cadena. Finalmente, el valor a imprimir es el primer argumento de la función sys_execve, que resulta ser el comando que se ejecuta. La traza anterior se generó ejecutando «man ls» en un shell separado. Como puede ver, man ejecuta una serie de programas adicionales para finalmente mostrar la página de manual.
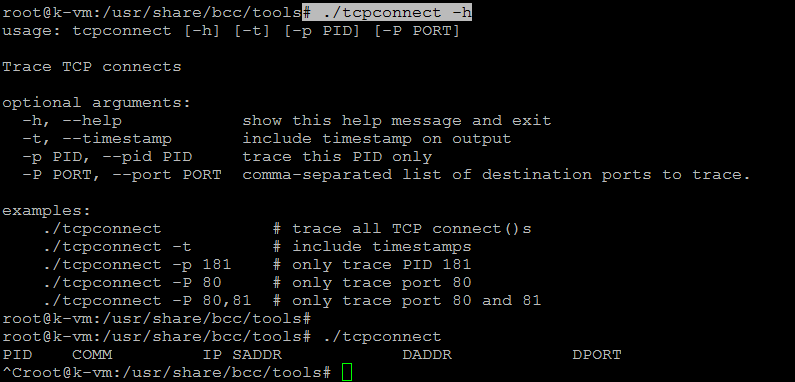
24) tcpconnect
Realiza un seguimiento de las conexiones TCP activas (por ejemplo, a través de un connect () syscall) y muestra la latencia (tiempo) de la conexión medida localmente. Esta es una métrica de rendimiento útil que generalmente abarca el procesamiento TCP / IP del kernel y el tiempo de ida y vuelta de la red (no el tiempo de ejecución de la aplicación). Esta herramienta funciona mediante el seguimiento dinámico del kernel de las funciones de TCP / IP y deberá actualizarse para que coincida con los cambios que se realicen en estas funciones. Esta herramienta debe actualizarse en el futuro para usar puntos de rastreo estáticos, una vez que estén disponibles.
Ejecute el siguiente comando para obtener más ayuda sobre su uso.
# ./tcpconnect -h
Conclusión
BCC es uno de los mejores kits de herramientas para rastrear y monitorear el nivel de rendimiento de los sistemas Linux. Proporciona más de 50 herramientas de monitoreo de sistemas y redes que se puede utilizar con diferentes parámetros para rastrear la información requerida en el sistema. BCC viene con una fácil instalación en cualquier sistema Linux, mientras que hay suficientes manuales de soporte disponibles para obtener ayuda sobre las herramientas y técnicas disponibles. Espero que este artículo haya sido de mucha ayuda, comencemos a usarlo en su propio sistema y compartamos su experiencia.