Cómo instalar varios nodos Elasticssearch en un solo servidor
Elasticsearch es un motor de búsqueda de código abierto, ampliamente distribuible, fácilmente escalable y de nivel empresarial al que se puede acceder a través de una API extensa y elaborada. Puede impulsar búsquedas extremadamente rápidas que respaldan sus aplicaciones de descubrimiento de datos y se puede utilizar para muchos casos de uso diferentes, como búsqueda de texto completo «clásica», almacenamiento de análisis, autocompletar, corrector ortográfico, motor de alertas y como almacén de documentos de propósito general. . Las cargas de trabajo analíticas tienden a contar cosas y resumir la gran cantidad de datos que incluso podrían ser Big Data. Puede utilizarlo para búsquedas difusas, que son indulgentes con los errores ortográficos. Siempre es importante probar los cambios y las mejoras en sus búsquedas con cantidades realistas de datos antes de enviarlas a producción, ya que las búsquedas difusas consumen mucha CPU, por lo que deben agregarse con cuidado y probablemente no en todos los campos. Elasticsearch también ayuda en la finalización automática y la búsqueda instantánea. La búsqueda mientras los tipos de usuario vienen en muchas formas, como pueden ser sugerencias simples de, por ejemplo, etiquetas existentes, intentar predecir una búsqueda basada en el historial de búsqueda o simplemente hacer una búsqueda completamente nueva para cada pulsación de tecla acelerada. Hay muchas características diferentes en Elasticsearch para ayudar a construir estas características, como match_phrase_prefix, consultas de prefijos, índices de gramos y una familia de sugerencias diferentes.
Este artículo trata sobre la instalación de varios nodos de Elasticsearch en un solo servidor CentOS 7.
Pero puede utilizar pasos similares para ejecutarlos en sus otras distribuciones de Linux.
Prerrequisitos
Para realizar esta tarea de instalar y configurar más de un nodo Elasticsearch en un solo servidor, solo necesita acceder a su servidor usando las credenciales de usuario raíz, puede ser CentOS 6 o CentOS 7, cualquier servidor que desee usar para su entorno. Conectémonos a su servidor y creemos un usuario general no root primero.
#ssh root@server_ip
1) Agregar nuevo usuario
Después de iniciar sesión con el usuario root, utilice los siguientes comandos para crear un nuevo usuario de propósito general que se utilizará durante la instalación.
# adduser elasticsearch
Changing password for user elasticsearch. New password:**** Retype new password: **** passwd: all authentication tokens updated successfully.
Agregue el nuevo usuario al grupo ‘rueda’ para darle privilegios de sudo.
# usermod -aG wheel elasticsearch
2) Actualización del sistema
Ahora actualice su sistema con actualizaciones y parches de seguridad usando el siguiente comando en su servidor CentOS 7.
# yum update -y
Una vez que su sistema esté listo con los requisitos previos, continúe con el siguiente paso para la instalación de Java Versión 8 en su sistema.
3) Instalación de Java (JVM) Versión 8
Elasticsearch está construido con Java que requiere al menos Java 8 para ejecutarse. Solo se admiten Java de Oracle y OpenJDK. Se debe usar la misma versión de JVM en todos los nodos y clientes de Elasticsearch. Por lo tanto, se recomienda que se instale la versión 1.8.0_121 de Java o posterior, de lo contrario Elasticsearch se negará a iniciarse si se utiliza cualquier otra versión de Java.
Para instalar la versión requerida de JAVA, puede usar el siguiente comando.
$sudo yum install java-1.8.0-openjdk.x86_64
Una vez finalizada la instalación, ejecute el siguiente comando y compruebe la versión del archivo java instalado.
$ java -version
java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
La versión de Java que usará Elasticsearch se puede configurar configurando la variable de entorno ‘JAVA_HOME’. Una vez que se hayan completado los requisitos previos, pase a la sesión de red para descargar, instalar y luego configurar los nodos.
Cómo descargar Elasticsearch
Elasticsearch se proporciona en varios formatos de paquete, pero los paquetes ‘zip’ y ‘tar.gz’ son adecuados para su instalación en cualquier sistema, que es la opción más fácil para comenzar con Elasticsearch. El paquete ‘rpm’ es más adecuado para la instalación en Red Hat, Centos, SLES, OpenSuSE y otros sistemas basados en RPM. Se puede descargar desde el sitio web Elasticsearch o desde nuestro repositorio RPM usando comandos ‘wget’.
Descarguemos las dos versiones diferentes del paquete Elastisearch que instalaremos en CentOS 7.
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.tar.gz
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.0.1.tar.gz
Ahora tenemos dos versiones diferentes de paquetes Elasticsearch disponibles para instalar. Extraiga los archivos y muévase a la carpeta extraída para compilar e instalar el paquete.
$ tar -zxf elasticsearch-5.0.1.tar.gz
$ tar -zxf elasticsearch-5.2.2.tar.gz
Configurar el primer nodo de Elasticsearch
Ahora comience con la última versión de Elasticsearch que se instalará primero. Vamos a abrir el archivo de configuración predeterminado usando su editor de línea de comandos ubicado en el directorio ‘config’.
$ vim elasticsearch-5.2.2/config/elasticsearch.yml
Presione ‘i’ para cambiar al modo de inserción e inserte los siguientes parámetros de configuración en el archivo.
cluster.name: elastic_cluster1 node.name: node-1 node.master: true node.data: true transport.host: localhost transport.tcp.port: 9300 http.port: 9200 network.host: 0.0.0.0
Aquí, http.port y transport.port no se especifican en la configuración predeterminada, ES intenta elegir el siguiente puerto disponible al inicio, comenzando en una base de 9200 para HTTP y 9300 para su transporte interno. Guardemos y cerremos el archivo de configuración usando ‘: wq!’ y ahora configura tu nodo secundario.
Configurar nodo secundario
Para configurar su nodo secundario, abra el mismo archivo de configuración ubicado en la ubicación predeterminada del archivo e inserte el siguiente contenido en él usando su editor.
$ vim elasticsearch-5.0.1/config/elasticsearch.yml
cluster.name: elastic_cluster1 node.name: node-2 #node.master: true node.data: true transport.host: localhost transport.tcp.port: 9302 http.port: 9202 network.host: 0.0.0.0
Guarde y cierre el archivo y pase a la siguiente sección para iniciar sus servicios.
Cómo iniciar los servicios de Elasticsearch
Como hemos configurado ambos nodos de Elasticsearch con diferentes versiones, ahora necesitamos iniciar ambos en nuestro servidor CentOS 7 ejecutando su script binario.
$ cd elasticsearch-5.2.2
$ bin/elasticsearch -d
Esto iniciará el proceso de búsqueda elástica en segundo plano. Ahora cambie su directorio al nodo secundario de elasticsearch y ejecute los mismos comandos.
$ cd elasticsearch-5.0.1
$ bin/elasticsearch -d
Eso es todo, ahora puede verificar el estado de sus puertos de escucha para asegurarse de que ambos nodos se estén ejecutando en sus puertos específicos mencionados en la configuración.
$ netstat -tlnp
$ ps -ef | grep elastic
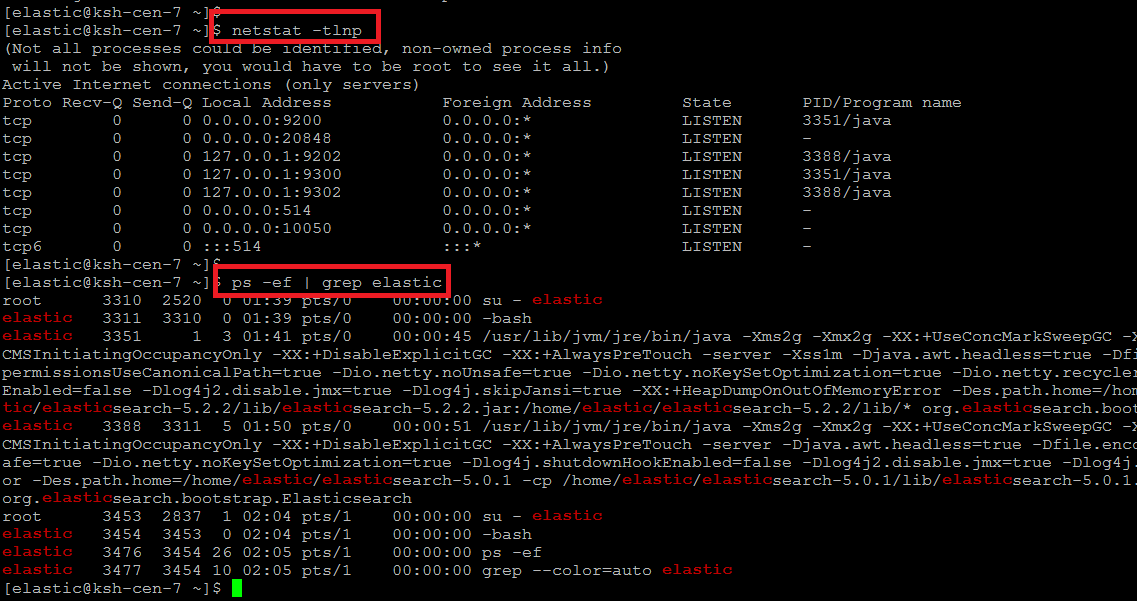
También puede utilizar el siguiente comando para confirmar que el servicio se ha iniciado correctamente.
$ curl -X GET 'http://localhost:9200'
{
"name" : "node-1",
"cluster_name" : "elastic_cluster1",
"cluster_uuid" : "yrMHCKfJS2msgvQj-HWkag",
"version" : {
"number" : "5.2.2",
"build_hash" : "f9d9b74",
"build_date" : "2017-02-24T17:26:45.835Z",
"build_snapshot" : false,
"lucene_version" : "6.4.1"
},
"tagline" : "You Know, for Search"
}
De manera similar, para el nodo secundario que se ejecuta en el puerto ‘9202’, use el siguiente comando.
$ curl -X GET 'http://localhost:9202'
{
"name" : "node-2",
"cluster_name" : "elastic_cluster1",
"cluster_uuid" : "I4Xk5Yr3RTuyp0Q0IsmxNQ",
"version" : {
"number" : "5.0.1",
"build_hash" : "080bb47",
"build_date" : "2016-11-11T22:08:49.812Z",
"build_snapshot" : false,
"lucene_version" : "6.2.1"
},
"tagline" : "You Know, for Search"
}
Conclusión
Eso es. En este artículo, hemos aprendido sobre la instalación de varios nodos de elasticsearch en un solo servidor CentOS 7. Ahora puede usar Elasticsearch en varias configuraciones diferentes para Logstash, algunos usos de análisis, potenciando la búsqueda orientada al usuario en índices grandes y muchas aplicaciones internas. La gestión de JVM con grandes montones es un negocio aterrador debido a los tiempos de ejecución de la recolección de basura. Es mejor tener montones aún más pequeños, ya que es más fácil capturar y analizar volcados de montón. Para obtener un rendimiento óptimo de Lucene, también es importante tener suficiente RAM disponible para el almacenamiento en caché de los archivos de índice del sistema operativo. Si ejecutamos un solo nodo con un montón pequeño, estaríamos desperdiciando tanto CPU como RAM.